Redis에게 캐시 잘 먹이는 방법 – 캐시 스탬피드와 핫키

시작은 캐시는 과연 무적일까?라는 궁금증에서였다.
대부분의 백엔드 시스템은 캐시를 사용한다. 그런데 캐시는 잘 쓰면 성능을 극적으로 끌어올리지만 잘못 쓰면 오히려 DB를 한순간에 죽이는 폭탄이 되어버린다.
대표적인 사례가 바로 캐시 스탬피드(Cache Stampede)와 특정 key 하나에 요청이 몰리는 핫키(Hot Key) 문제다.
이러한 사례를 직접 재현해보고 어떻게 해결할 수 있는지 알아본 과정을 기록한 글이다.
캐시 스탬피드와 핫키 만료
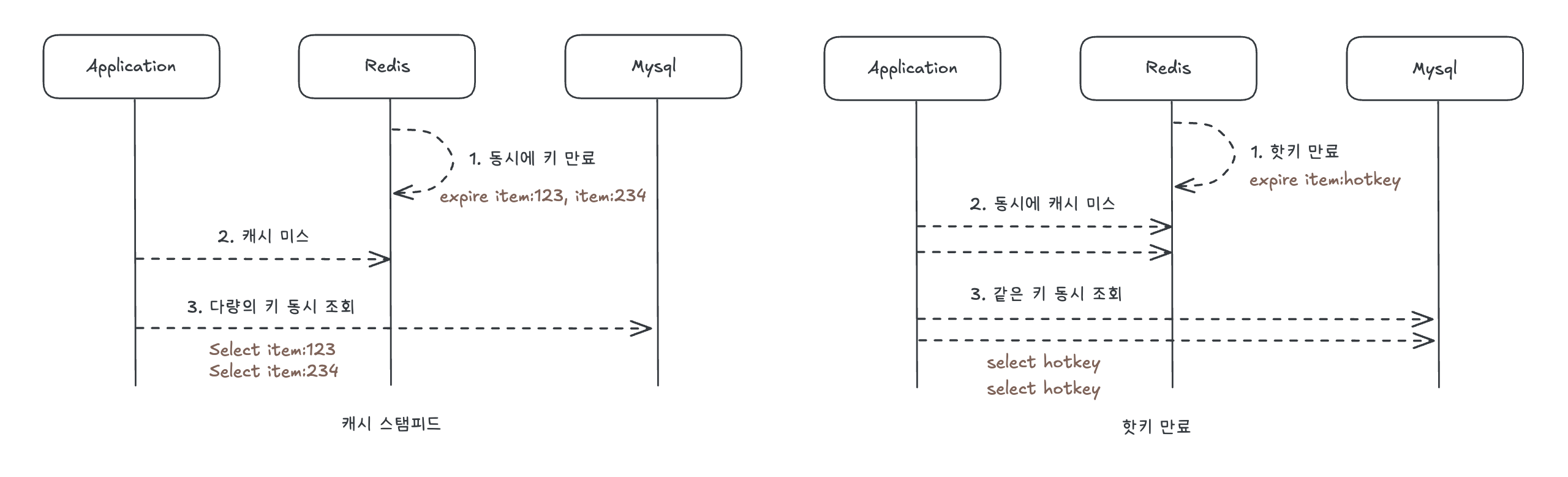
캐시 스탬피드
TTL 만료 시점에 다수 요청이 동시에 캐시를 조회하고 캐시 미스가 발생해 DB로 폭주하는 상황을 이야기한다.
- 모종의 사유로, 다량의 키가 같은 TTL을 가짐
- 평시에는 캐시를 정상적으로 사용
- 캐시가 만료 순간 1~2초 동안 모든 요청이 동시에 DB로 몰리는 상황
핫키 만료
핫키란 요청이 몰리는 특정 key를 이야기하는데 인기상품, 인기 컨텐츠등을 생각하면 이해하기 쉽다.
만료 순간에 여러 요청이 동시에 같은 키의 데이터베이스를 조회하게 되며 큰 부하가 데이터베이스에 부하되게 된다.
또한 이 상황에서 중복되서 캐시를 쓰기 때문에 정합성 및 캐시 자원도 소모하게 된다.
키가 만료되어 데이터베이스로 한번에 부하가 이전된다라는 같은 점때문에 헷갈릴수도 있지만
- 여러 키가 한번에 조회되는가 = 캐시스탬피드
- 한 키에서 여러번 조회되는가 = 핫키 만료
로 구분하면 쉽게 생각할 수 있다.
물론 두개의 상황이 겹쳐진다면 훨씬 더 영향이 커지게되는것은 덤
먼저 캐시스탬피드 먼저 알아보도록 해보자
환경 구성
- 메인 비즈니스 로직 구성
SpringBoot, Redis, Mysql - 테스트 데이터 수집
Mysqld-exporter, prometheus, grafana
간단하게 구성은 다음과 같다, QPS를 수집하기 위해 Mysqld-exporter, prometheus, grafana를 사용하여 모니터링을 구성하였다.
테스트 시나리오 구성
TTL = 10s로 설정
캐시 스탬피드
- 100개의 키를 캐시 주입 후 캐시 만료 대기, 이후 동시에 n(100)개의 키를 동시에 조회
- 100개의 키(쓰레드)가 60초 동안 100ms간격으로 계속해서 조회
핫키 만료
- 캐시 주입 후 캐시 만료 대기, 이후 동시에 n(100)개의 쓰레드가 동시에 조회
- 100개의 키를 대상으로 키당 5개의 쓰레드가 60초 동안 100ms간격으로 계속해서 조회
1번째 시나리오는 문제 현상을 확인하기 위해 일회성으로 구현하였고
2번째 시나리오는 실제 트래픽을 몰리는 상황을 가정하여 시나리오를 구성해보았다.
캐시 스탬피드
먼저 캐시 스탬피드 증상을 확인해보고 어떻게 개선할 수 있는지 확인해보고자 한다.
캐시 스탬피드 확인
만료시 동시에 조회되는 경우를 확인하면 캐시스탬피드가 어떤 증상을 보이는지 확인할 수 있다.
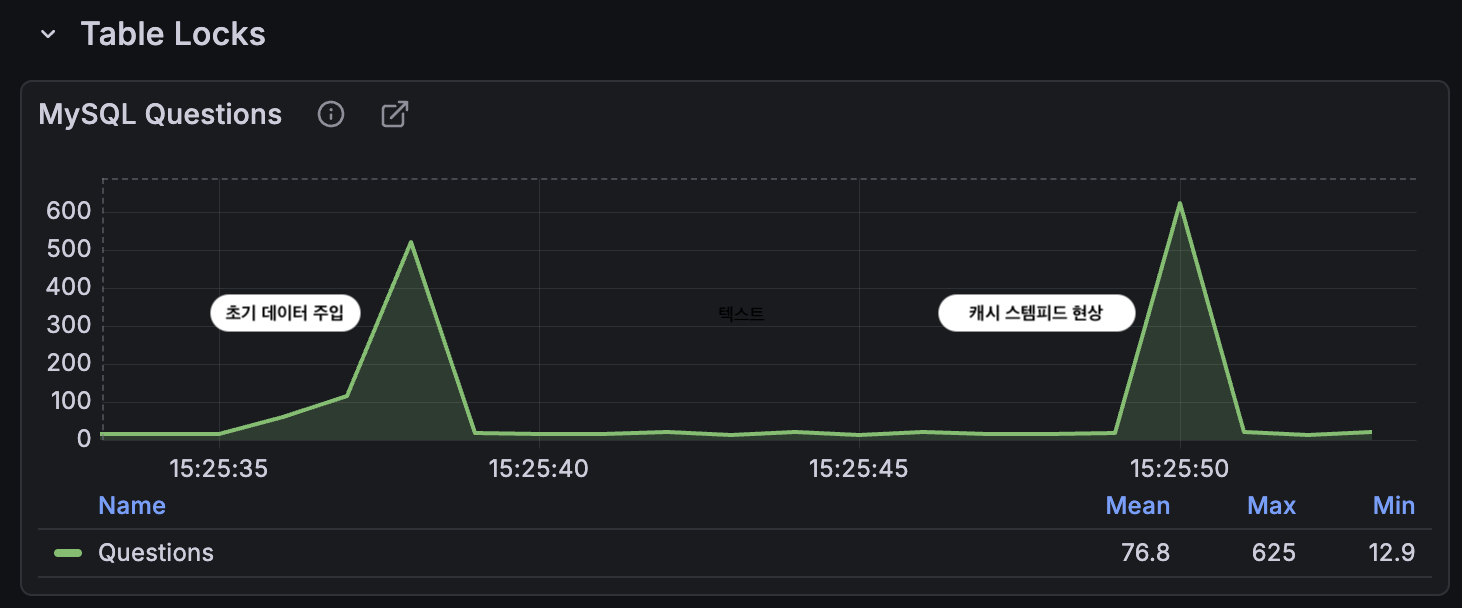
초기 데이터가 캐시에 넣은지 10초뒤 캐시가 만료 되었을때 동시 DB를 조회함으로써 QPS가 증가하는 것을 볼 수 있다.
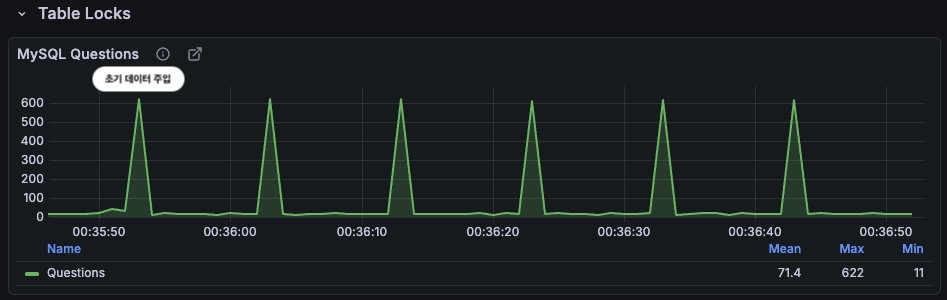
이러한 현상은 실제와 비슷한 시나리오에서 더욱 도드라지게 보여지는데 캐시가 만료 될때마다 지속적으로 QPS 600으로 뛰는 모습을 볼 수 있다.
캐시 TTL이 10초였기 때문에 TTL 만료 직후 1초 동안 QPS가 약 평균 10 → 600으로 수직 상승했다.
매 10초마다 약 600 QPS의 스파이크가 반복되는데 이 패턴은 단기적 문제로 끝나는 것이 아니라 지속적으로 DB에 충격을 가하는 구조다. 실제 서비스에서는 이러한 주기적 폭발이 슬로우쿼리 증가 → connection pool 고갈 → 장애로 이어질 수 있다.
지터(Jitter)를 적용해보자
캐시 스탬피드는 여러 키에서 동시에 캐시가 만료되어 나오는 증상이다.
캐시 만료 시간을 무작위로 조금 지연시킨다면 캐시 스탬피드 상황에서도 데이터베이스의 부하를 균등하게 분산시킬 수 있다.
지터는 TTL을 무작위의 짧은 시간을 캐시 만료 시간에 더해서 부하를 분산 시키는 역할을 한다.
// Jitter 예시
Duration ttl = Duration.ofSeconds(8 + ThreadLocalRandom.current().nextLong(0, 4));
redisTemplate.opsForValue().set(key, item, ttl);
return item;
바로 결과를 확인해보자
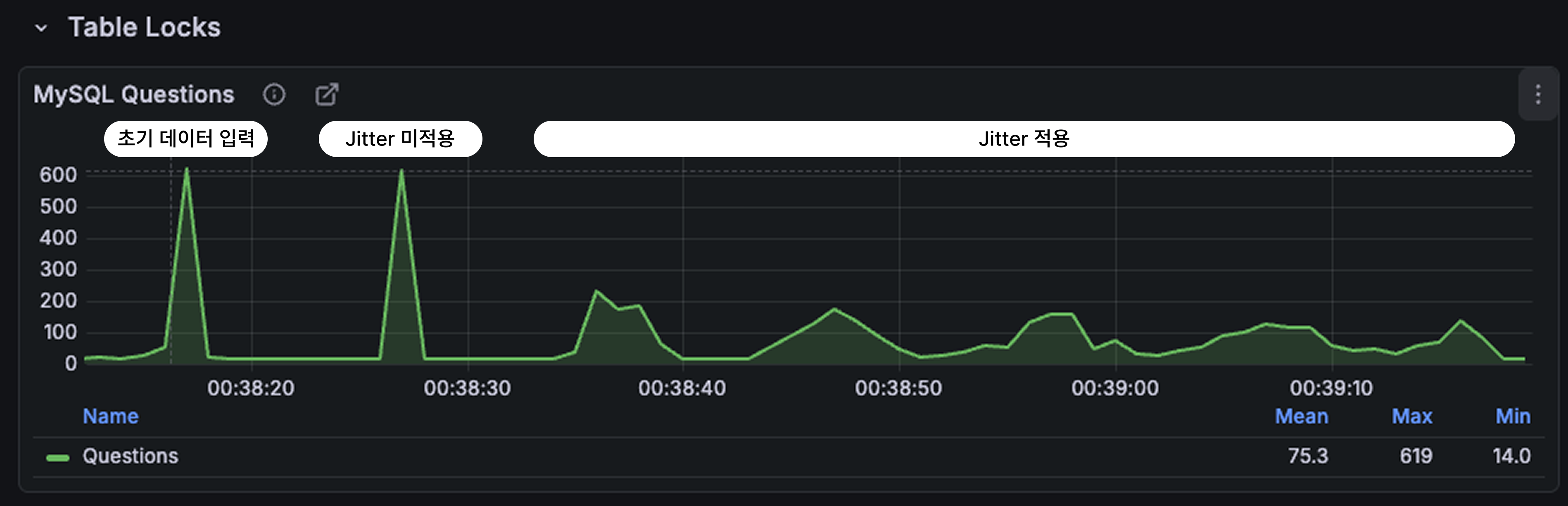
처음 QPS상승은 초기 데이터 조회 및 캐싱을 위한 부하증가이며 두번째는 처음 캐싱에 Jitter가 적용되어 있지 않아 동시에 만료되어 부하가 증가된 현상이다.
이후부터 Jitter가 적용한 이후 TTL이 모두 같은 시간이 아니라 8초 ~ 12초 범위에서 균등하게 퍼지도록 설정된다. 그 결과 만료 구간에서 발생했던 600 QPS의 뾰족한 spike가 완전히 사라지고 QPS 200 수준으로 3~4초 동안 고르게 분산되는 형태로 변화했다.
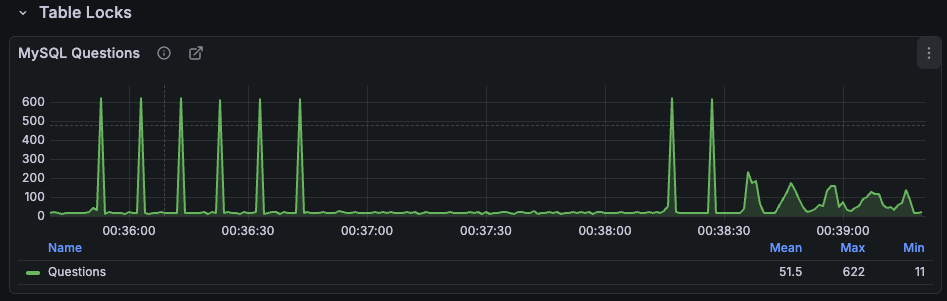
이 두 그래프를 비교하면 차이가 극명하다.
- Jitter 미적용: TTL 만료 구간마다 QPS가 600까지 치솟으며 가시처럼 세로 spike가 나타난다.
- Jitter 적용: 같은 상황에서도 peak가 최대 200 수준으로 줄어들고 spike가 아니라 부드러운 능선 형태로 나타난다.
선 계산(PER 알고리즘)
Jitter 말고도 다른 방법이 존재하는데 바로 PER 알고리즘을 활용한 선 계산 방법이다.
Jitter은 랜덤성으로 TTL을 지정하여 부하는 나누는 한편 선계산 방식은 키가 실제로 만료되기 전에 이 값을 갱신함으로 부하를 최소화한다.
## 선 계산 sudo코드
def fetch(key):
ttl = redis.ttl(key)
if ttl - (random() * expiry_gap) < 0 :
value = db.fetch(key)
redis.set(value, KEY_TTL)
return value
...
PER 알고리즘은 이러한 선계상 방식에 적용할 수 있는 확률적 조기 재계산 알고리즘이다.
currentTime - (timeToCompute * beta * log(rand())) > expriy
간단하게 다음과 같이 요약할 수 있는데 만료 시간에 가까워질 수록 true를 반환할 확률이 증가하므로 불필요한 쿼리를 효과적으로 방지하는 방안이 될 수 있다.
핫키 만료
핫키 증상 확인
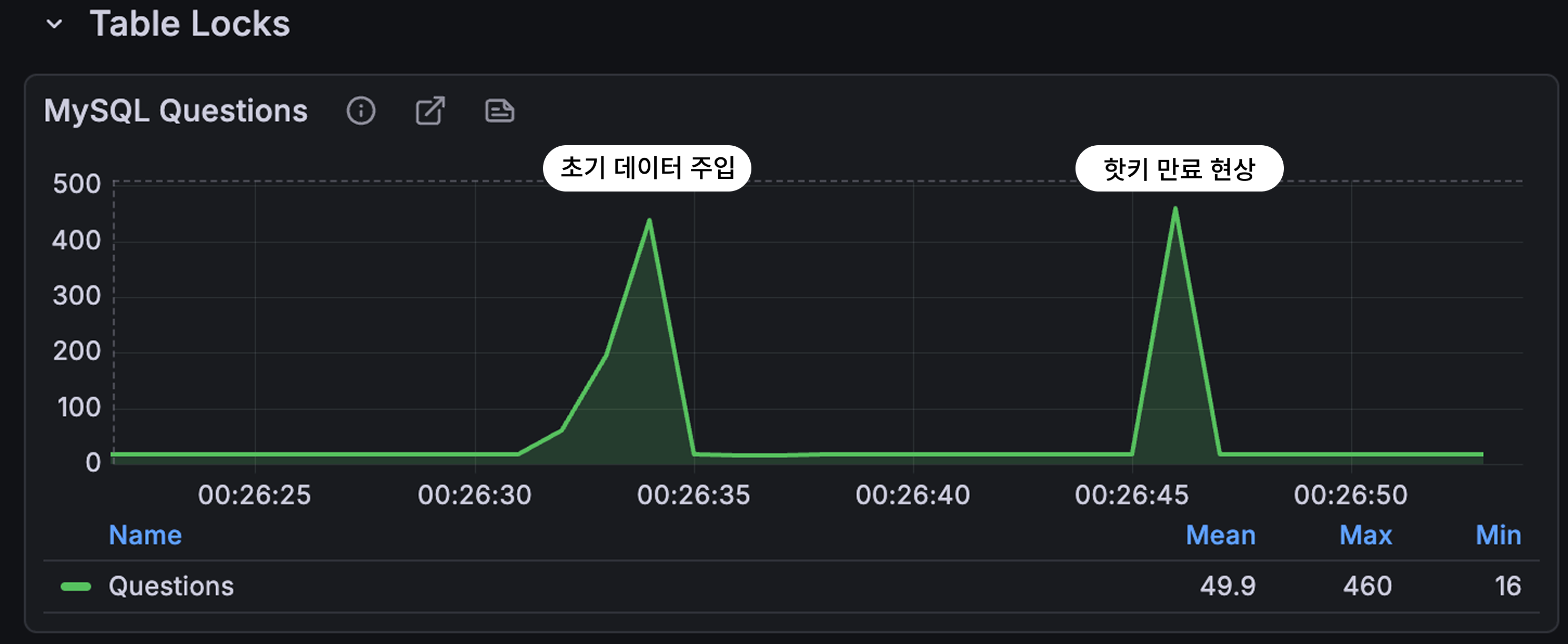
하나의 키를 가지고 실험 후 확인한 결과이다. 초기 데이터 주입은 기존의 코드를 활용한 상황으로 1~100의 아이템들을 모두 조회하여 캐시에 넣는 구조를 가지고 있다.
흥미로운 점은 단 하나의 키가 만료되었을 때 발생한 QPS(약 500)가 100개의 서로 다른 키가 동시에 조회할 때의 QPS(약 500)와 동일하다는 것이다.
이러한 현상은 핫키 만료 상황에서
- 수많은 요청이 같은 키를 재조회
- 캐시 미스가 한 번만 발생하지 않고
- N개의 요청이 N번 DB를 때리는 구조라는 점을 보여준다.

cache miss를 카운트하였을때도 캐시를 사용하면서 의도했던 miss보다 더욱 큰 것을 확인할 수 있다.
그렇다면 지속적으로 요청이 발생할때는 어떨까?
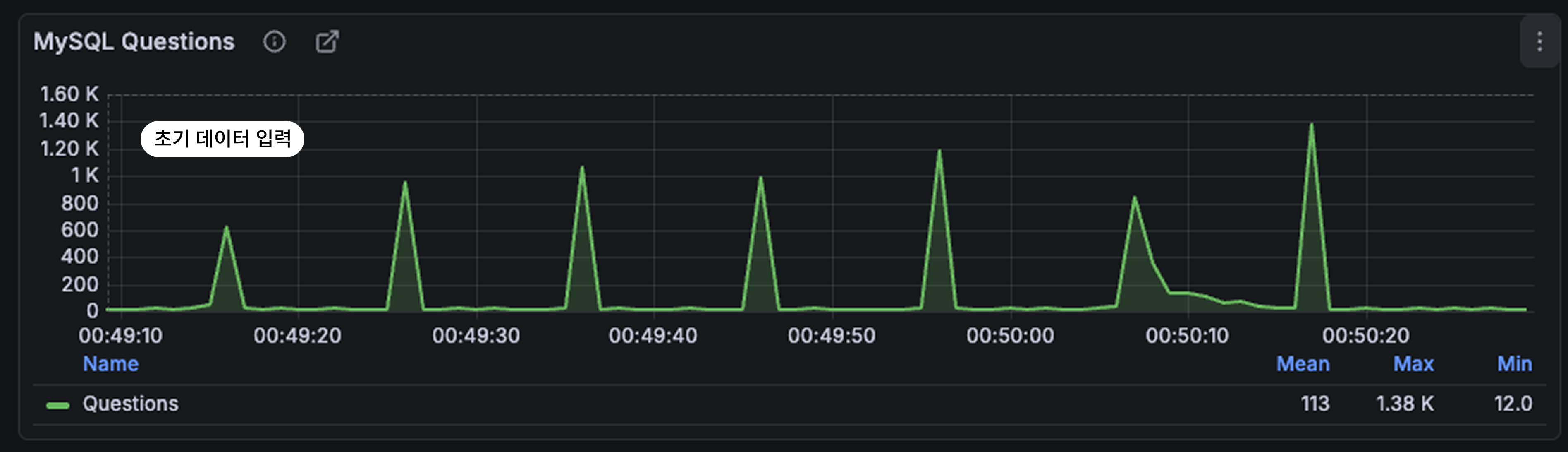
캐시 스탬피드 현상과 비슷하게 핫키가 만료될때마다 지속적으로 QPS가 1K대로 급증하는 현상을 확인할 수 있다.
(다만 해당 그래프에서 지터가 적용되어 있지 않아 캐시스탬피드 현상도 같이 일어나는 것으로 예상됨)
Lock을 이용하여 해결해보자
Lock을 사용하게 된다면 이러한 핫키 문제를 방지할 수 있다. 갑자기 Lock이라고 하면 헷갈릴만한데(내가 그랬다...) 우리가 알고있는 공유자원을 다룰 때 사용하는 락의 개념과 비슷한 원리이다.
캐시의 자원을 공유자원으로 취급하며 캐시 미스가 발생하였을때 락을 설정하고 캐싱을 업데이트한 후 락을 해제함으로써 한 번의 쓰기작업만 처리하도록 유도하는 것이다.
실제 적용에는 redisson을 활용하였고 다음과 같은 sudo 코드로 구현할 수 있다.
String lockeKey = "lock:item:" + id;
RLock lock = redissonClient.getLock(lockeKey);
locked = lock.tryLock(500, TimeUnit.MILLISECONDS);
Item item = itemRepository.findById(id)
.orElseThrow(() -> new IllegalArgumentException("아이템이 없습니다. id=" + id));
cache.put(id, item);
return item;
바로 적용 결과를 확인해보자
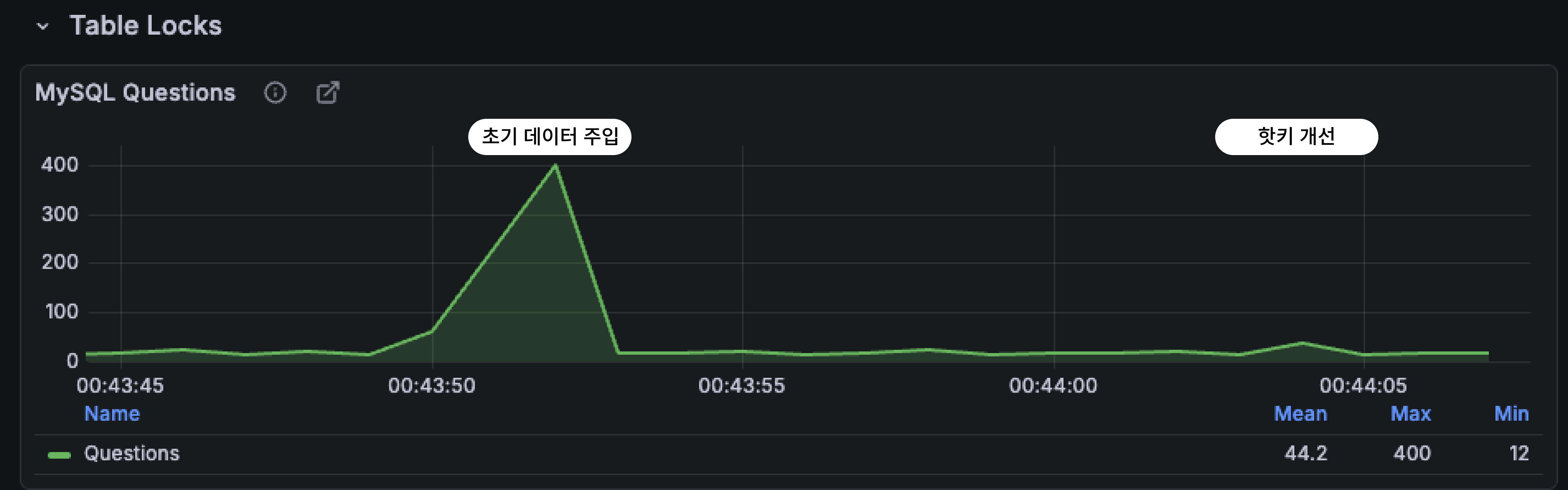

이전과 비교하였을때 확실히 QPS가 낮아졌다. cache miss count 또한 확인하였을때 의도하던대로 중복된 키에 대해서는 1번의 쿼리만 나가는 것을 확인할 수 있다.
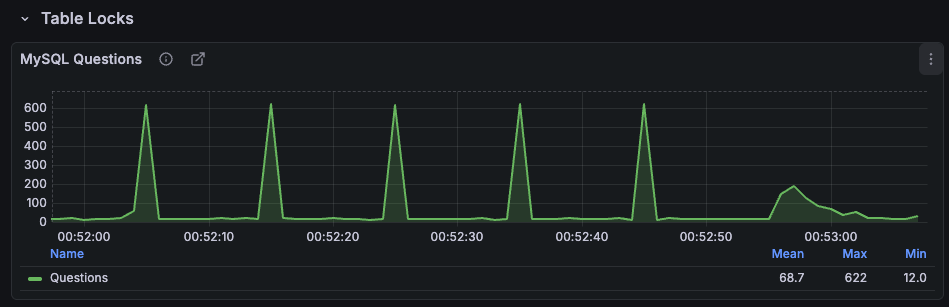
(지터 미적용으로 캐시 스탬피드 현상은 발생 중이다..)
락 적용 후 기존 평균 QPS 1K에서 QPS 600 수준으로 거의 절반에 가까이 감소한 것을 확인할 수 있다.
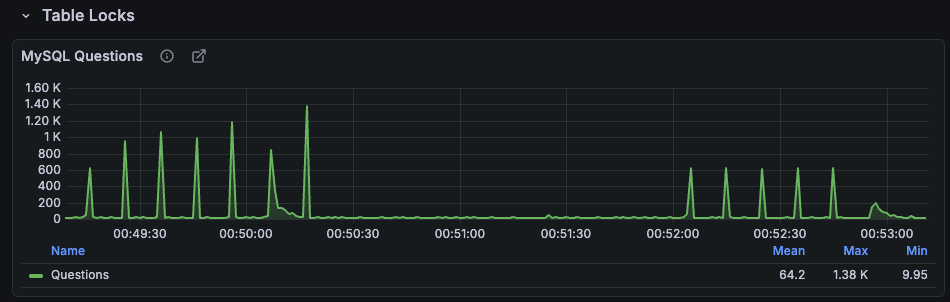
두개의 그래프를 같은 선상에서 비교해보면 QPS차이를 명확하게 느낄 수 있다.
- 락 미적용시 cache miss count

- 락 적용시 cache miss count

cache miss count 또한 락을 사용하지 않을때 큰 차이를 볼 수 있는데 약 2배정도의 쿼리를 추가로 조회하는 것 또한 확인할 수 있었다.
항상 락을 사용하면 될까?
락 방식의 경우에는 락 경쟁으로 lock wait 및 latency 증가를 고려해야한다.
실제 테스트 과정에서 많은 쓰레드를 설정하여(id당 100개의 스레드) lock을 잡지못하고 예외가 발생한 경우도 있었다.
따라서 핫키 상황에서 이를 고려하여 제한적으로 적용하는 것이 이상적이다.
실무에서 캐시 문제가 발생하였을때 어떤 문제를 확인할 수 있을까?
지금까지는 QPS증가를 확인하기 위해서 감당 가능한 부하를 부하하여 테스트하였다. 과연 그 이상의 부하가 일어나면 어떤 현상이 발생할까?
요청이 예상치 못하게 증가할 수 있는 실무 상황에서는 어떤 현상이 발생하는지를 확인하기 위해 더 많은 부하로 진행하여 확인해보고자 하였으나...
생각보다 DB의 부하 저항성이 강했다...
실패한 이유는 다름과 같다.
1. 서버 애플리케이션의 자원 부족
현재의 테스트는 Junit으로 스레드를 생성하여 부하는 진행하는 방식이다. 너무 많은 부하를 스레드를 생성하니 테스트를 위한 스레드로 OOM이 발생하였다.
그래도 시스템 전체적인 자원 부족을 유도하여 어느 정도 문제점을 확인할 수 있었다.
(밑에 정리하여 기술)
2. 생각보다 강한 DB 부하 저항성
k6로 테스트 도구를 분산하여 진행하였으나 socket connection pool이 먼저 소진되어 실험이 불가하였다. 서버가 분산 환경이라면 DB로 부하가 전이되어 증상을 확인할 수 있을 것으로 예상된다.
실제에서는 어떤 증상이 발생할까?
확실한 결과를 얻기위한 실험에는 실패했지만 어느정도 발생할 수 있는 결과를 예측할 수 있었다. 이러한 정보와 함께 추가로 조사한 정보를 바탕으로 정리하면서 마무리하고자 한다.
먼저 실험에서 얻은 결과는 타임아웃으로 인한 결과가 발생했으며 일정 시간이 지난 후 복구 되었다는 것이다.
캐시가 만료된 시점에 급격한 처리 요청을 처리하며 밀린 테스크들에 타임아웃이 발생하며 캐시가 다시 채워졌을때 잠시 오류가 발생하지 않았다.
이러한 현상이 TTL 기준으로 지속해서 반복한다는 것을 확인할 수 있었다.
전체적인 증상을 정리하자면 다음과 같다.
- 일정 주기로 QPS 스파이크 발생
- 일정 주기로 latency 증가
- 일정 주기로 타임아웃으로 인한 요청 불가 발생
- 문제가 발생된 후 일정 시간이 지난 후 자동 복귀되나 일정 주기시 문제 재발생
추가적으로 일정키에서 집중적으로 이러한 현상이 보인다면 핫키 만료 문제를 의심해볼 수 있을 것 같다.
다만 실무에서는 트래픽 증가로 인한 서버 자원 부족, DB 슬로우 쿼리, Redis 네트워크 지연, 이벤트 루프 정체 등으로 파악할 수도 있기 때문에 캐시 문제를 바로 파악하기에는 어려운 부분이 많지 않을까 싶다.
마무리
이번 실험은 단순히 “캐시 스탬피드와 핫키가 이런 문제다”라는 이론을 확인하려는 것이 아니었다. 실제 환경을 만들어 놓고 직접 부하를 걸어 보니 글로만 봤던 개념들이 눈앞에서 그대로 재현되는 경험을 할 수 있었다.
특히 캐시는 “빠른 데이터”를 제공하는 도구라고만 생각했는데 처음으로 캐시 자체가 또 하나의 시스템 부하 지점이 될 수 있다는 사실을 체감하게 되었다.
캐시를 단순한 옵션이 아니라 서비스 구조 전체를 결정하는 중요한 요소로 다시 바라보게 되었다. 앞으로도 기능을 구현하는 것뿐만 아니라 그 기능이 어떤 부하와 어떤 패턴으로 동작할지까지 고민하는 개발자가 되어야겠다는 생각으로 마무리한다.