GPT은 직접 사드세요... 제발 - GPT 1

(AI를 잘모르는 백엔드 엔지니어 수준으로 진행한 후 프로젝트입니다.)
GPT은 직접 사드세요... 제발
개요
이전 부터 GPT를 조금이나마 공부해본적도 있었고 GPT를 사용한 프로젝트를 진행해본 경험은 있었지만 직접적으로 모델을 만들어본 경험은 없었다. 사실 LLM, Large Language Model이라는 단어를 고려해봤을때 직접 만들기는 크게 어려운 부분이 존재한다.
다만, 이번 기회를 빌려 작은 GPT 모델이라도 만들어보고 직접 어떻게 동작하는지 확인해보고자 시작하였다.
이렇게 시작하여 지금부터
- 간단한 GPT 모델 구현
- 한국어 모델 구현 시도
- 특정 기능을 수행하는 GPT 모델 구현
까지 이어지는 여정을 이야기해보자 한다.
사전 학습
당연하게도 한번도 아는 내용이 아니였기에 나도 GPT에 대해 사전학습(pretrained)가 필요하였다.
(정말 많은 시간을 사용하며 학습하였지만, 그 과정은 중요한 내용이 아니기에 어떤 자료를 참고하였는지 설명 후 넘어가고자 한다.)
- 대형언어모델(LLM) 바닥부터 만들기
- Build a Large Language Model (From Scratch)
- 3Blue1Brown 한국어 : 생성형 모델 시리즈
- llm.c
- GPT-2: Unsupervised Multitask Language Learning 논문
- DeepSeek-R1: Architecture of MLA and MoE 논문
- DeepSeek-R1: Model Architecture
주로 개념을 학습하고자 하였고 논문은 Notebooklm을 사용하여 참고 정도로 확인하였다.
간단한 GPT 모델 구현
일단 먼저 LLM이 구현을 직접해보는 것이 중요하다고 생각하였다. 부족한 지식으로도 구현이 가능할지도 의문이였고 가지고 있는 자원(RTX 4060)으로 구현이 가능한지도 확인해봐야했다.
대형언어모델(LLM) 바닥부터 만들기
Build a Large Language Model (From Scratch)
이 자료를 참고면서 진행하였고 가장 간단한 모델로 해리포터 책을 학습하여 일정 단어를 입력할시 문장을 생성하는 GPT 모델이다.
1. 데이터 셋
데이터 셋은 캐글에서 제공하는 해리포터 책을 이용하였고 이미 학습에 사용할 수 있도록 문장별로 잘라져있는 버전이 있어 쉽게 전처리없이 쉽게 사용할 수 있었다.
2. 토크나이저 및 모델 구성
자료에 나와있는 토크나이저 및 모델 구성을 그대로 사용하였고 GPT-2 토크나이저 및 모델 구조를 그대로 사용하는 형태이다.
3. 학습
학습에 사용한 데이터 셋의 크기는 약 12만 토큰 정도의 크기이며 학습은 10epoch 정도로 진행하여 2~3시간 남짓 걸렸다.
4. 결과
"Dobby is a" 입력값에 대해 출력값을 가져온 결과이다.
0 : Dobby is a house-elf.…” “What does this mean, Albus?” Professor McGonagall asked urgently. “It means finding out Veronica Sm to the whole body sort of Gryffindor dormitwick let out
1 : Dobby is a house-elf.…” said Harry. “Well, whoever owns him will be an old wizarding family, and they’ll be ready to be rich,’ll be rich,’ll be rich,�
2 : Dobby is a house-elf.…” The voice was growing fainter. Harry was sure it was moving away — moving upward. A mixture of fear spreading up to bewattle cauldron was that he looked dream team how it was stretched out
3 : Dobby is a house-elf.…” The voice was growing fainter. Harry was sure it was moving away — moving upward. A mixture of fear spreading up to beaming once more curious people kept waking in the whole body of fear spreading up
4 : Dobby is a house-elf.…” said Harry. “Well, whoever owns him will be an old wizarding family, and they’ll be ready to be rich,” said it’ll be rich, as quickly st
5 : Dobby is a house-elf.…” The voice was growing fainter. Harry was sure it was moving away — moving upward. A mixture of fear spreading up to beaming once more curious people kept waking up portable, it was moving upward,
6 : Dobby is a girls’ toilet.” “Oh, Ron, there won’t be anyone in there,” said Hermione standing up and he said Hermione standing up and then, watching them as they saw the car. “Listen
7 : Dobby is a house-elf.…” said Harry. “Well, whoever owns him will be an old wizarding family, and they’ll be ready to be rich,” said cauldron as they” said Lockhart�
8 : Dobby is a house-elf.…” said Harry. “Well, whoever owns him will be an old wizarding family, and they’ll be ready to be rich,’ll be rich,’ll beaming my new
9 : Dobby is a house-elf.…” said Harry. “Well, whoever owns him will be an old wizarding family, and they’ll be ready to be rich,’ll beheaded,’ll be rich,�
결과를 참고하였을때 문법적으로 이상한 부분도 있고, 내용자체가 이상한 부분도 있다. 실제 데이터셋에서 입력값을 검색해보면 입력값 주변에서 출력된 단어들를 찾아볼 수 있었다.
비록 정확하지 않지만 생각보다 빠르게 간단한 GPT 모델을 만들어보자는 목표가 달성되었다!
한국어 모델 구현 시도
이전의 간단한 모델을 구현하면서 한국어 모델을 직접 만들어 볼 수 있겠다라는 생각이 들었고 바로 다음 목표로 진행하였다.
목표는 이전의 책의 내용을 찾아 생성하는 모델이 아닌 우리가 GPT를 사용하듯이 채팅을 주고 받을 수 있는 한국어 GPT 모델을 만들어보고자 하는 것이 목표였다.
하지만 다음과 같은 이유로 목표를 변경할 수 밖에 없었다.
자원의 한정
GPT는 학습한 내용을 바탕으로 다음 단어를 예측하는 것이라고 많이 말하고는 한다.
지난 단계의 모델 결과를 확인하며 학습한 데이터를 바탕으로 다음 단어를 선택하는 것이 무엇인지 체감할 수 있었다.
출력된 내용 자체가 책의 내용의 의존적인 부분이 많이 보였다.
즉 우리가 기존에 사용하는 형태의 GPT 모델을 구현하기 위해서는 책의 내용보다 많은 내용이 있는 데이터가 필요했다.
책은 정해진 스토리를 진행하기 때문에 어떻게 보면 단어의 순서가 한정적인 문제를 푸는 모델이다. 하지만 일상적인 소통은 전체적인 맥락에 따라서 단어의 순서가 매우 많아지기 때문에 많은 데이터가 필요할 뿐만아니라 문법의 정확한 구성을 위해서는 많은 학습이 필요하게 된다고 판단했다.
작지만 강한 Kanana Nano 효율적으로 개발하기
밑바닥부터 Kanana LLM 개발하기: Pre-training
대규모 구매도서 기반 한국어 말뭉치 데이터
(한국어에 유리한 모델, 학습에 사용한 데이터셋 등 한국어 모델을 구현하기 위해 찾아본 정보들)
실제 한국어 모델인 Kanana를 구현할때 사용한 말뭉치(데이터셋)의 크기는 5T Token을 사용하였다는 정보 또한 확인할 수 있었다.
이러한 사항을 고려하였을때 120K 토큰 수보다 수천배에 달하는 데이터를 학습해야하는데 이미 120K Token을 학습하는데 3시간을 사용한 상황을 고려하였을때 학습에만 모든 시간을 사용할 것이 다름없어 보였다.
역량의 한정
더 많은 학습데이터를 학습하기 위해서는 이를 이해하고 푸는 GPT 모델 또한 개선될 필요가 있었다. 즉 더욱 어려운 문제를 고민하기 위해 뇌의 크기를 늘려야한다고 비유할 수 있을 것 같다.
현재는 구현된 모델의 성능을 비교하는 기술적인 방법을 학습해야 했으며 이러한 내용을 분석해야하고 또한 모델을 개선하는 방법 또한 학습해야했다. 시간적인 자원을 고려했을때 너무 큰 목표로 인해 실패확률이 높다고 판단하였다.
특정 기능을 수행하는 GPT 모델
우연찮게 프랑스 연구소에서 PlelAS가 만든 Baguettotron(331M)에서 H100 단 10대로 좋은 성능의 GPT를 만들었다는 내용을 보게 되었다.
Baguettotron - huggingface 모델 내용
해당 연구소의 비결은 합성데이터, 즉 인터넷 전체를 긁어모든 더티데이터가 아니라, 위키피디아 기반으로 만든 고품질 합성데티어로 200B 토큰만 훈련 시켰다는 것이였다. 해당 글을 살펴보며 잘 정제된 데이터를 사용한다면 작은 모델이라도 좋은 성능이 나올 것 같다는 생각이들었다.
잘 정제된 데이터를 고민하던 중 프로그래밍된 코드의 인풋과 아웃풋이 어느정도 바운드리 안에서 정제된 데이터이지 않을까와 함께 우테코에서 진행한 미션들이 떠올랐다.
로또 미션을 다시 살펴보면 로또번호, 당첨 번호, 보너스 번호의 정규화된 형태로 입력을 받고 발행한 로또 수량, 발급된 로또 번호, 당첨 내역, 수익률을 정규화된 형태로 출력받게 된다.
또한 데이터 또한 정해진 바운드리에서 나오기 때문에 정제된 데이터셋 또한 만들기에 용이하였다.
바로 다음 목표로 특정 기능을 수행하는 GPT 모델을 구현하는 것으로 목표를 세우고 진행하였다.
가설 설정
처음으로 진행한 것은 가설을 설정하는 것이였다.
정제된 데이터셋을 이용할 경우 작은 데이터셋, 작은 모델 크기에서도 프로그래밍 로직을 수행할 수 있다.
라는 가설을 설정하고 진행하였다.
수행할 기능 설정
매우 간단하게 계산기 정도를 구현할 수도 있었으나 이전에 바로 진행한 로또 자판기를 구현해보는 것으로 설정하였다.
로또 문제는 생각보다 컴퓨터에게 가혹하다.
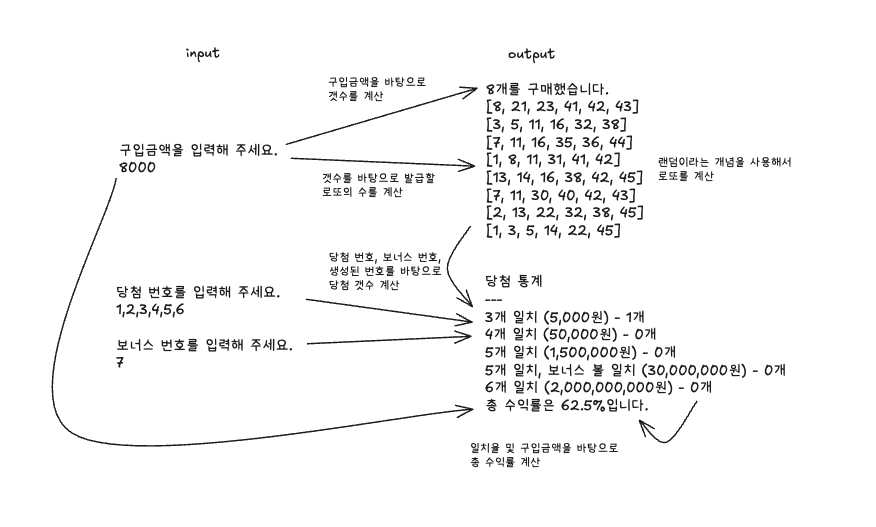
다음은 로또 문제를 풀기 위해서 진행해야하는 연산들을 가식화한 도표이다.
많은 연산이 복잡하게 엮여있기에 가설을 테스트하기에 적합한 예제라고 생각하였다.
데이터셋 구성의 용이성
또한 이미 프로그래밍 기법으로 제작한 코드가 존재하기 때문에 데이터셋을 구성하기에 적합하다고 판단하였다.
여기까지가 일단 특정 기능을 수행하는 모델 구현까지의 목표를 수정해서 달성한 1단계 였다.
내용이 너무 길어져 가장 몰입했던 모델을 구현하고 학습하면서 진행한 시행착오를 다음글에서 이야기 해보고자 한다.