GPT은 직접 사드세요... 제발 - GPT 2

(AI를 잘모르는 백엔드 엔지니어 수준으로 진행한 후 프로젝트입니다.)
GPT은 직접 사드세요... 제발
개요
- 데이터 생성
- 모델 Pre-training
- n차 개선 학습
- 모델 테스트
현재 글에서 모델을 구현하는데 고민하였던 여러 사항들을 간단하게 이야기하고 결과를 확인해보고자 한다.
데이터 생성
입출력 형식 정의
이미 로또 미션을 진행해본 상황으로 입출력 형태의 정의는 잡혀있는 상태이다.
구입금액을 입력해 주세요.
8000
8개를 구매했습니다.
[8, 21, 23, 41, 42, 43]
[3, 5, 11, 16, 32, 38]
[7, 11, 16, 35, 36, 44]
[1, 8, 11, 31, 41, 42]
[13, 14, 16, 38, 42, 45]
[7, 11, 30, 40, 42, 43]
[2, 13, 22, 32, 38, 45]
[1, 3, 5, 14, 22, 45]
당첨 번호를 입력해 주세요.
1,2,3,4,5,6
보너스 번호를 입력해 주세요.
7
당첨 통계
---
3개 일치 (5,000원) - 1개
4개 일치 (50,000원) - 0개
5개 일치 (1,500,000원) - 0개
5개 일치, 보너스 볼 일치 (30,000,000원) - 0개
6개 일치 (2,000,000,000원) - 0개
총 수익률은 62.5%입니다.
다만 다음과 같이 입출력이 섞여있는 형태이다.
- 구입금액 입력
- 구입갯수 출력
- 생성된 번호 출력
- 당첨 번호 입력
- ...
LLM 특성상 인풋 -> 아웃풋으로 출력되기 때문에 입출력의 용이성을 위해 입출력 형식의 개선이 필요했다.
<IN>
구입금액={money}
당첨번호={w1,w2,w3,w4,w5,w6}
보너스번호={bonus}
</IN>
###
<OUT>
티켓수={ticket_count}
구매번호:
{ticket1}
{ticket2}
...
3개일치={count3}
4개일치={count4}
5개일치={count5}
5개보너스일치={count5b}
6개일치={count6}
수익률={rate}%
</OUT>
따라서 다음과 같은 형태로 입출력 형태를 재정의 하였다.
또한 ### 구분자를 추가하여 입력과 출력을 구분하였다.
다만 추가 특이사항으로
예외에 대한 처리는 데이터 셋에서 제외하였다.
학습시간을 최소화하는 것이 가장 큰 관건이라고 생각하였고 가설이 검증될 경우 예외 케이스 추가 및 추가학습으로 예외처리 사항도 가능할 것이라고 예상 했기 때문이다.
데이터 셋은 얼마나 필요할까?
- 디버그/프로토타입용: 5k–10k 샘플
- 실험/논문화 가능한 최소선: 20k–50k 샘플
- 충분히 안정적인 학습: 50k–100k 샘플
정도로 기준점을 마련한 후 가장 작은 단위부터 진행하는 것이 학습 시간 고려, 잘못된 데이터셋 개선, 모델 구조 개선 측면에서 좋다고 판단하였다.
토큰 수를 계산해 보았을때
money=8000 ( ~ 12자 )
winning=1,2,3,4,5,6 ( ~ 20자 )
bonus=7 ( ~ 8자 )
### ( ~ 3자 )
티켓수=8 ( ~ 6자 )
구매번호: ( ~ 5자 )
[8,21,23,41,42,43] ( ~ 18자 ) × 티켓수(최대 20개라 쳐도 평균 10개 미만)
...
3개일치=1 ( ~ 8자 ) × 5줄
수익률=62.5% ( ~ 10자 )
샘플 하나당 200~400글자로 예상하였고
- 10k 샘플 → 약 2M–4M 토큰
- 50k 샘플 → 약 10M–20M 토큰
- 100k 샘플 → 약 20M–40M 토큰
각 샘플당 이러한 토큰 수를 가지게 된다.
모델 Pre-training
토크나이저 선정
기본적으로 많이 사용하는 토크나이저 중 각각 장단점 비교 후 선택하였다.
출력에 한국어가 사용되기 때문에 한국어 토크나이저를 기준으로 비교하여 선택하였다.
-
GPT-2
한글, 숫자, 기호, 줄바꿈 모두 안정적으로 처리
미니 모델 적절한 토큰 수 -
skt/kogpt2-base-v2
한국어 SentencePiece 기반 → 한글 처리 매우 안정적
vocab_size 약 51k → GPT2와 비슷 -
EXAONE tokenizer (LGAI-EXAONE/ExaOne-3.5-7.8B-Instruct) 한국어 특화에서 가장 좋은 성능을 보임 vocab_size 약 500k
최종적으로는 GPT-2를 그대로 사용하였는데 이유는 다음과 같았다.
- GPT-2
기존에 만들어봤던 모델에서 사용했기 때문에 시행착오가 적을 것으로 판단 - skt/kogpt2-base-v2
데이터 셋 특성상 특수 문자 패턴이 반복되는 로또 데이터에서는 GPT2 tokenizer와 큰 차이 없음
굳이 가중치가 조금 더 흔들려있는 KoGPT2를 사용해야 할까라는 의문점 - EXAONE tokenizer (LGAI-EXAONE/ExaOne-3.5-7.8B-Instruct)
vocab_size 약 500k 엄청 큼 → 과도한 vocab 규모라고 판단하여 사용 X
pad_token 설정
LLM은 batch 단위로 학습하며 지정한 max_len=256이라면 모든 문장은 길이가 정확히 256토큰이여야한다.
이전 해리포터 모델과는 다르게 로또 생성기의 경우에는 끝나는 지점이 정해져 있다. 그렇기 때문에 모든 문장의 길이가 동일할 수는 없다.
- 해리포터 모델
Dobby is a가 입력으로 주어지면 책이 끝나는 부분이 아니라면 계속해서 일졍한 부분을 채우게된다. - 로또 자판기 수익률=11.1% 출력되었다면 이 다음에 출력할 부분은 없음
따라서 나머지 부분을 채우기 위해 pad_token이란 것을 사용하게 된다.
모델 구조 선정
이 부분에서 많은 내용이 있어야하지만 크게 변경된 사항은 없이 이전 구조를 사용하였다.
즉, GPT-2 논문 트랜스포머 블록 구조랑 거의 동일하게 사용하였는데 아직 추가적인 지식에 대한 학습이 필요한 부분이기도하고, 간단한 모델에서 시작해서 추가적인 사항을 추가하는 것이 중요하다고 판단하였기 때문이였다.
학습
epoch 30으로 진행하였고, RTX 4060을 사용하여 8시간 정도 소요 되었다.
[Epoch 001] train_loss=1.3327, val_loss=0.9760
[Epoch 002] train_loss=1.1994, val_loss=0.9647
[Epoch 003] train_loss=1.0896, val_loss=0.9421
...
[Epoch 028] train_loss=0.7817, val_loss=0.7795
[Epoch 029] train_loss=0.7805, val_loss=0.7783
[Epoch 030] train_loss=0.7798, val_loss=0.7781
loss 또한 꾸준히 하락하였고 과적합 또한 보이지 않았다.
결과
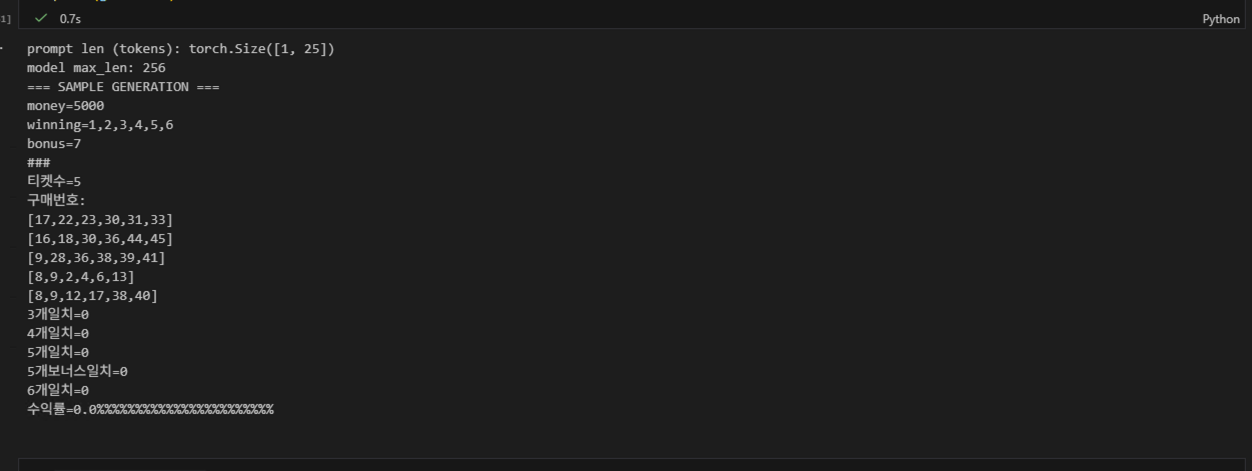
어느 정도 형태를 띄는 긍정적인 결과값을 확인할 수 있었다 !!
입력된 금액을 바탕으로 티켓수, 구매번호를 갯수에 맞게 출력했고 n개 일치 항목, 수익률 항목에 대해 형식을 잘 출력하는 것을 볼 수 있다.
n차 개선 학습
1차 모델 개선
1. repetition loop
수익률 부분에서 출력값이 이상한 것을 확인할 수 있었다.
수익률 =0.0%%%%%%%%%%%%%%%
마지막에 %이 계속해서 반복되며 출력되는 현상으로 멈춰야하는 신호를 주지않았기 때문에 발생한 문제
멈춤 신호인 EOS토큰을 stop 조건으로 안쓰지 않았고 학습과정에서 eos 토큰을 따로 붙여준 적이 없었기 때문에 데이터셋을 로드하는 LottoDataset 객체를 수정하여 마지막에 eos토큰이 추가되도록 수정하였다.
(EOS 토큰 부분에서 모델학습만 3~4번 반복하였는데 기존 코드를 삭제하지 않아 누락되었던 것은 비밀...)
2. 출력값 제한으로 인한 짤림 문제
max_len을 256으로 설정하여 진행하였는데 입력 금액이 많아질 경우 출력 토큰 제한으로 출력이 짤리는 문제가 발생하였다.
money=18000
winning=1,2,3,4,5,6
...
[4,20,22,32,39,40]
[11,13,20
이런식으로 마지막 부분이 짤려 정상적인 출력이 되지않는 상황이였다.
max_len은 학습시간과 연관이 있어 무제한으로 키우기는 어려우니 최소 상한 금액을 20000원으로 가정하고
max_len을 512로 수정하여 진행하였다.
max_len=256
→ 총 토큰 = 10,000 × 256 = 2.56M tokens
max_len=512
→ 총 토큰 = 10,000 × 512 = 5.12M tokens
토큰 수 변화가 2배로 뛰게 되었다.
2-1. 출력값 증가로 인한 메모리 부족현상 발생
출력값이 두배로 뛰면서 input으로 사용되는 데이터 크기 또한 두배로 커졌고 이에 따라 GPU의 메모리에서 OOM이 발생하는 현상이 발생하였다.
GPU 메모리 한계를 극복하기 위해 Gradient Accumulation를 적용하여 자원의 한계를 해결하고자 하였다.
Gradient Accumulation는 간단하게 기존 배치를 작은 배치(학습단위)로 줄인 후 작은 배치에서 계산된 loss를 누적하여 정해진 횟수에 도달할 경우 그때 가중치를 업데이트하는 방식이다.
기존 batch size = 32 -> batch size = 8, accum_steps = 4로 수정하여
(batch 8 * 4 = effective 32) 기존의 32 batch와 동일한 효과를 낼 수 있도록 수정하였다.
2차 모델 개선
2차 부터는 각 기능이 제대로 동작하는가를 체크하였다.
1. 당첨번호 계산 과적합 문제 해결
money=5000
winning=1,2,3,4,5,6
bonus=7
...
[4,5,6,25,27,44]
3개일치=0
n개 일치 항목에 대해 카운트가 잘 되지않는 현상이였다. 모든 간이 테스트에서 일치하는 항목이 나오지 않았다.
로또의 확률을 생각해보면 그 답을 알 수 있었는데, 로또 번호는 기본적으로 당첨 확률이 굉장히 낮은 분포를 보인다.
이 때문에 n개 일치 항목에 대한 데이터셋에는 일치 항목이 0인 데이터셋이 많아지게된다.
즉 많은 데이터가 일치항목에서 0을 띄기 때문에 gpt는 해당 패턴을 기준으로 0이 정답이라는 기준을 세우게 되는 것이다.
(값이 있더라도 loss가 낮기 때문에 해당 부분이 무시되게됨)
일치 항목에 대해서 0에 과적합이 되는 것이다.
이를 해결하기 위해 데이터셋 생성 부분에서 일정한 비율로 당첨번호가 꼭 나오도록 생성에 대한 조건을 추가하여 학습하였다.
FORCE_HIT_PROB = 0.3 # 당첨 비율 설정(30%)
if random.random() < FORCE_HIT_PROB and ticket_count > 0:
# 어떤 등수를 넣을지 가중치로 선택
rank_candidates = ["3", "4", "5", "5b", "6"]
# 3개/4개 정도를 많이, 5/5b/6은 조금만
rank_weights = [0.4, 0.2, 0.2, 0.1, 0.1]
rank = random.choices(rank_candidates, weights=rank_weights, k=1)[0]
# 티켓 중 하나 골라서 그 자리를 "해당 등수 티켓"으로 바꿈
idx = random.randrange(ticket_count)
tickets[idx] = generate_ticket_with_rank(winning, bonus, rank)
2. 수익률 부분 추가 데이터 제공
수익률 또한 높은 확률로 계산하지 못하였는데 너무나 근거없는 수치가 나오는 경우의 수가 많았다.
데이터 셋을 확인하였을때 수익률 계산에 대한 근거가 부족하다는 생각이 들었다.
3개일치={count3}
4개일치={count4}
5개일치={count5}
5개보너스일치={count5b}
6개일치={count6}
수익률={rate}%
지금 형태는 이런 형태인데 n개 일치에 따라서 따라오는 금액이 얼마인지 데이터셋에서 찾기 힘들었다.
따라서 일치시 얻게되는 금액을 추가하여 gpt가 해당 금액을 계산(패턴학습)할 수 있도록 추가하였다.
3개일치 (5000원) = 0
4개일치 (50000원) = 0
5개일치 (1500000원) = 0
5개보너스일치 (30000000원) = 0
6개일치 (2000000000원) = 0
수익률=0.0%
3차 모델 개선
수익률 부분에서는 높은 일치율을 보였지만 당첨번호 계산 부분에서는 아직도 낮은 일치율을 보였다.
Task-Aware Weighted Loss, Token-level Weighting,Curriculum by Masking 으로 불리는 어려운 부분에 가중치를 더욱 크게 부여하는 것이 해결책으로 판단하였다.
즉 loss를 보았을때 감소하는 추세이나 모든 토큰이 똑같이 1.0의 가중치로 loss에 들어가기 떄문에 똑같은 가중치로 하였을때 정해져있는 포맷부분(money=, winning=, 숫자 쉼표, 티켓수= 등)은 잘맞추어 loss가 떨어지고 마지막인 당첨갯수, 수익률 부분은 대충 때려맞추고 있어도 loss에 반영되지 않은 현상이 발생하는 것으로 예상하였다.
따라서 모델 구성을 변경하여 마지막 tail_len을 계산후 지정하여 해당 부분이 더 높은 가중치를 가지도록 변경하였다.
4차 모델 개선
당첨번호 계산 부분에서 추가적인 효과가 없어 데이터 셋의 크기를 늘려 추가적인 학습이 반영되도록 개선하였다.
- 10k 샘플 → 약 2M–4M 토큰
- 50k 샘플 → 약 10M–20M 토큰
- 150k 샘플 → 약 40M–60M 토큰
학습량을 지속적으로 늘려 진행했고 그 과정 속에서 기능이 동작하는지 확인하였으나 큰 효과를 얻기는 어려웠다.
모델 테스트
테스트 정의
기존 LLm을 테스트하기 위해 여러 방법이 있는 것으로 알고 있다.
- MMLU
- KMMLU
- HAERAE
- HumanEval
- MBPP
- GSM8K
다만 프로그래밍적인 요소, 출력 형태의 고정으로 새로운 테스트를 정의해야한다고 생각하였다.
출력한 형태와 기능을 만족하는가 두가지를 기준으로 테스트 기준을 재설정하였다.
1. 형식/파싱 레벨
1-1. 티켓수 형식
- 티켓수 = N 이 존재하는지
- N이 정수로 파싱되는지
1-2. 구매번호 줄 형식
- 구매번호: 라인이 존재하는지
- 그 아래에 [...] 형태의 줄들이 있는지
- 각 줄에서 숫자를 파싱할 수 있는지
1-3. 라벨(결과) 줄 형식
- 아래 항목이 모두 존재하고 숫자로 파싱되는지
- 3개일치 (...) = X
- 4개일치 (...) = Y
- 5개일치 (...) = Z
- 5개보너스일치 (...) = A
- 6개일치 (...) = B
- 수익률 = R%
2. 내부 일관성 레벨
2-1. 티켓수 일관성
- 티켓수 = 실제 구매번호 줄 개수가 같은지
2-2. 구매번호 자체 유효성
- 각 줄에 숫자가 정확히 6개인지
- 한 줄 안에 중복 숫자가 없는지
- 각 숫자가 1~45 범위인지
3. 계산 정확도 레벨 (기능 테스트)
LLM 출력에 적힌 “결과 값들”이, 그 LLM이 출력한 “구매번호”로 실제 계산했을 때 맞는지.
3-1. n개 일치 수 계산 검증
- 구매번호 기반으로 다시 3/4/5/5b/6개 일치 개수를 계산
- 그 값이 LLM이 쓴 X, Y, Z, A, B와 각각 일치하는지
3-2. 수익률 계산 검증
- 이 값이 LLM이 쓴 수익률 = 실제 수익율
테스트 결과
=== TEST SUMMARY ===
n_total : 5000
n_ok : 2298 (성공)
n_fail : 2702 (실패)
n_format_fail : 293 (형식표현 실패)
n_logic_fail : 2409 (기능구현 실패)
ticket_count_parse_error : 0
ticket_lines_format_error : 2
result_labels_parse_error : 11
ticket_count_mismatch : 35
ticket_numbers_invalid : 245
match_stats_mismatch : 2408
roi_mismatch : 17
test_fail : 0
출력 형식 오류 분석
n_format_fail : 텍스트 출력 구조 문제
5000중 293건 → 형식 안정도 94%
n_format_fail에러 항목
- ticket_count_parse_error
티켓:숫자항목이 형식대로 출력되는가 - ticket_lines_format_error
구매번호:라인이 존재하는지 하위의구매번호: [:]생선된 구매번호 형식에 맞게 출력되었는지 - result_labels_parse_error
n개일치: ~ 수익률:의 항목이 형식대로 출력되는가 - ticket_count_mismatch
구매한티켓수 = 구매번호의 티켓수, 실제로 금액만큼 티켓을 구매하였는가 - ticket_numbers_invalid
구매번호가 올바른 형식인가(중복 X, 1~45)
각 항목에서 발생된 결과는 다음과 같다.
- format_fail : 293건, 5.86%
- lines error : 2건, 0.04%
- label parse error : 11건, 0.22%
- ticket_count_mismatch : 35건, 0.70%
- ticket_numbers_invalid : 245건, 4.90%
기능 구현 오류 분석
n_logic_fail : 기능 구현 오류 5000중 2409건 → 안정도 55%
match_stats_mismatch : 2408
그중 당첨번호 일치가 대분을 차지하는 모습을 보였음
n_logic_fail ≈ match_stats_mismatch 인 상황으로 수익률 부분 계산 부분은 0.34% 에러율을 보이며 매우 낮은 수치를
출력 포맷의 안정성과 수익률 수치 예측은 높은 정확도를 보였으나, 집합 비교 기반 연산 문제에서는 기능 구현 부분에서의 한계를 확인할 수 있었다.