GPT은 직접 사드세요... 제발 - GPT 3

(AI를 잘모르는 백엔드 엔지니어 수준으로 진행한 후 프로젝트입니다.)
GPT은 직접 사드세요... 제발
배포
마지막으로 누군가 레포지토리를 보고 구동해 볼 수 있는 패키지를 목표로 배포하는 과정으로 마무리를 지었다. AI모델 특성상 모델을 구동하기 위해 touch를 설치하여야 실행이 가능하다. 또한 Server형식인 경우에는 서버 코드에 대한 의존성도 설치되어야한다. 이를 용이하게 하기위해 도커를 이용하여 사용성이 쉽도록 배포하였다.
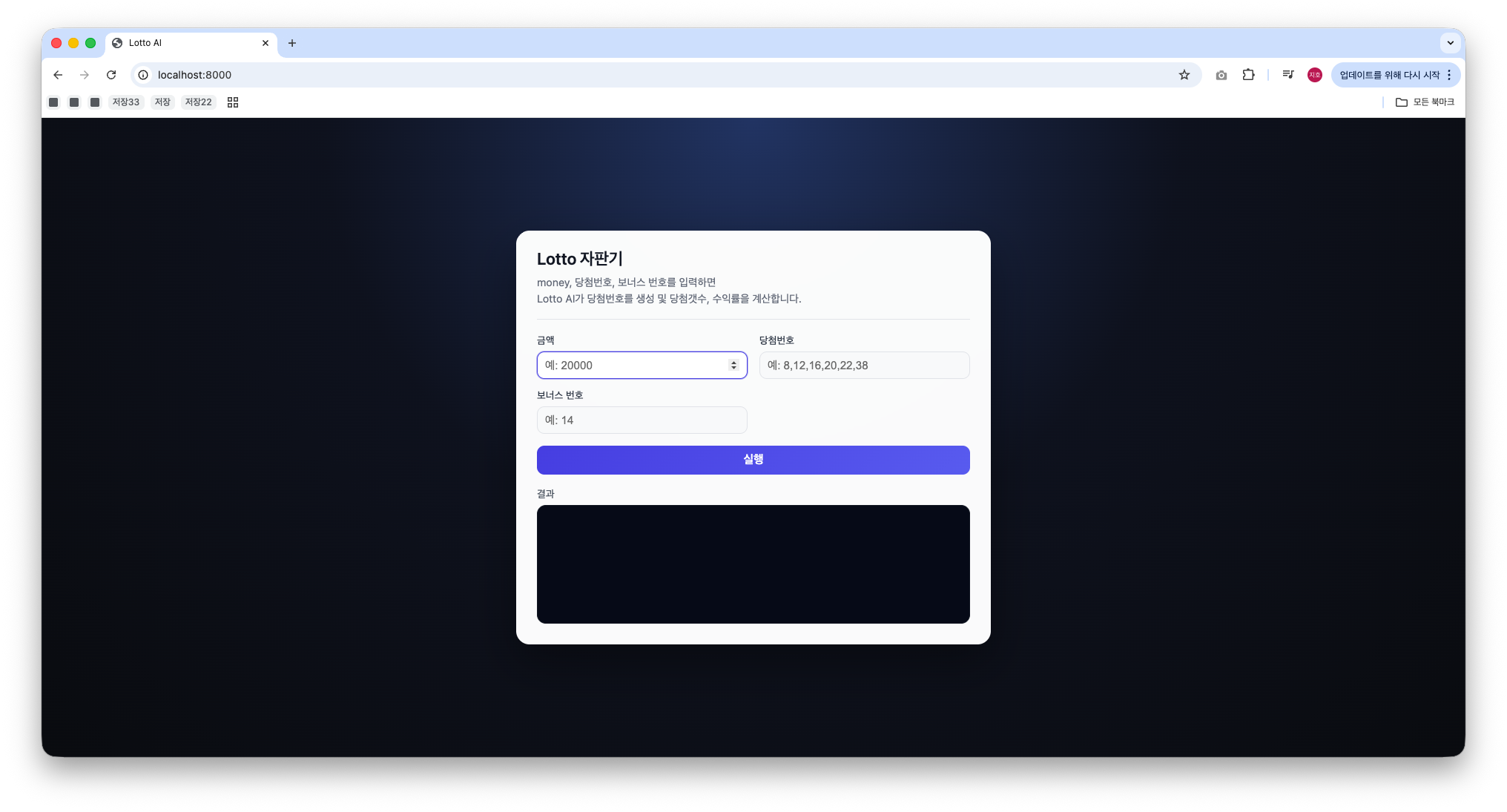
다만 실행과정을 쉽게 볼 수 있도록 cli버전도 구현하였고 cli로 실행, Fastapi를 활용한 서버 버전 두가지 버전으로 배포 버전을 만들어서 레포지토리에 올렸다.
결과
목표는 “작은 GPT 모델이, 정제된 데이터에서 ‘프로그래밍된 문제’를 얼마나 흉내 낼 수 있을까?”였다.
- 정상 동작: 약 46%
- 실패: 약 54%
그런데 이걸 단순히 실패 했다라고 말하기엔, 내부를 들여다보면 생각보다 재미있는 지점이 많았다.
- 출력 형식은 상당히 안정적으로 따라 했다.
- 수익률 계산은 의외로 높은 정확도를 보였다.
- 반면, “몇 개 일치했는지”에 대한 논리 계산이 실패의 대부분을 차지했다.
몇 개가 일치했는지 확인하기 위해서는 문자열 자체에서 확인할 요소가 많다.
당첨 번호와 보너스 번호를 바탕으로 생성한 각 로또 번호를 하나하나 비교하여 당첨갯수를 카운트 한 후 이를 바탕으로 해당 위치에 카운트한 숫자를 출력해야한다.
인풋 벡터에 많은 부분을 동시에 연산해야하기 때문에 작은 모델로는 한계점이 있을 수도 있고 GPT 구조를 고려하였을때 논리 계산이 어렵다는 점을 고려하면 처음부터 불가능 했던 시도였을 수도 있다.
실제 사용하는 ChatGpt의 연산과정을 찾아보니 연산 명령 실행시 가지고 있는 연산장치 즉 계산기를 바탕으로 수치적인 연산을 수행하는 것을 알 수 있었다.
결론적으로, 논리적 연산은 어렵지만 패턴 연산은 바탕으로 충분한 출력물을 뽑아낼 수 있다. 라는 것을 알 수 있었다.
의의
계속해서 모델을 개선하며 이러한 모델이 어떤 역할 할 수 있을까? 라는 고민을 하였다.
가장 많이 떠오른 생각은 굳이 모든 걸 거대 LLM에게 맞겨야할까? 라는 것이다.
누구나 가질 수 있는 단일 GPT 4060을 바탕으로 수십만 ~ 수백만 토큰 수준 데이터, 초소형 GPT 구조를 바탕으로 패턴학습에서 사용할만한 결과물을 얻어냈다.
조금 더 많은 연산 장치와 모델 개선이 이루어진다면 실 서비스에서 사용할만한 모델을 구현하기 쉬울 것으로 예상된다.
즉 구조가 정해진 출력, 도메인이 좁은 문제라면 위와 같은 초경량 특화 LLM이 선택지가 될 수 있지않을까 싶다.
또한 낮은 모델 크기 덕분에 실 서비스에서의 운용 비용 감소에서 효과를 얻을 수 있을 것이다.
후기
이번 프로젝트는 생각보다 더 낯선 경험이었다.
기존에는 백엔드 개발 위주의 경험만 있었고, 모델을 직접 설계하고 학습시키는 작업은 거의 처음에 가까웠다. LLM이라는 분야는 많이 들어보긴 했지만, 막상 바닥부터 구현하려니 “어디서부터 어떻게 접근해야 하는지”에 대한 감이 거의 없는 상태였다.
아는 내용이 없으니 체계적으로 접근하지 못했던 것 같다.
심지어 주피터 노트북을 사용했기 때문에 commit 단위도 어떻게 해야하는지 고민할 정도였고, 총합 5GB정도되는 모델 30개를 커밋하여 레포지토리를 초기화한 경험도 있었다.
특히 모델 학습 과정에서 큰 아쉬움이 남는다. 사전에 평가지표와 테스트 코드를 먼저 구현해 두었다면 해당 결과를 바탕으로 좀더 방향성을 가지고 빠르게 모델을 개선할 수 있지 않았을까 라는 아쉬움이 있다.
백엔드 개발에서는 어느 정도 “정답에 가까운 설계 패턴”이 있는데, 이 분야는 그런 기준점이 잘 보이지 않았다. 모델이 잘못된 건지, 데이터가 문제인지, 학습 방식이 문제인지 하나하나 직접 부딪쳐보지 않으면 알 수 없는 구조였다.
특히 인상 깊었던 건, 코드를 “잘 짠다”와 모델이 “잘 학습된다”는 감각이 완전히 다르다는 점이었다.
백엔드는 로직이 명확하다 보니 예측 가능한 방향으로 움직이는데, 모델 학습은 결과를 직접 보기 전까지는 상태를 정확히 알기 어려웠다. 몇 시간을 학습시킨 뒤 결과를 확인하는 과정이 반복되면서, 시간을 아무 생각 없이 쓰는 느낌이 들 때도 있었다.
그럼에도 불구하고 이 과정이 재미있었던 이유는 지금까지와는 전혀 다른 방식으로 문제를 바라보게 되었기 때문이다.
이전에는 “코드를 어떻게 설계할 것인가”가 중심이었다면, 이번에는 “이 문제를 데이터로 어떻게 표현할 것인가”를 고민하는 시간이 더 길었다. 문제를 코드가 아닌 데이터 구조로 설계한다는 경험 자체가 매우 새로웠다.
또 하나 크게 느낀 점은 ‘내가 모르는 분야에 직접 들어가 보는 경험’이 생각보다 가치 있다는 점이었다.
처음에는 구현이 서툴고, 방향도 자주 틀렸지만 그 과정 자체가 단순히 문서를 읽는 것보다 훨씬 많이 남았다. 이제는 LLM 관련 글이나 기술문서를 읽을 때, “아, 이 부분이 실제로 구현해보면 이런 느낌이었지” 하고 연결되는 감각이 생겼다.
결과적으로 이 프로젝트는 “완벽한 모델을 만들었다”는 성취감보다는 “새로운 세계에 직접 들어가 봤다”는 경험이 더 크게 남았다.
그리고 이 경험만으로도 충분히 해볼 가치가 있었다고 느끼며 이 글을 마무리한다.